
I built a tool to find news outlets that repeat debunked women’s health claims as if they were true. Here’s what it found, and what I learned building it.
TL;DR
- The tool scanned 3,064 news articles and flagged 187 that repeated previously-debunked claims as facts.
- Most flagged articles came from right-leaning outlets. But CNN, NewStatesman, and Vox were also flagged for repeating a Planned Parenthood safety comparison that other outlets had already debunked.
- Two claim campaigns account for most of the hits: abortion-pill reversal and the EPPC mifepristone-safety report. Both have been debunked by multiple outlets across the political spectrum.
- The tool is accurate (97.3%), but a human still has to review every flag before publishing. One specific error pattern makes that non-negotiable.
- Everything is public: github.com/rickramos1/ai-media-analysis-tool.
What I wanted to know
I kept seeing the same women’s health claims in news articles I’d already seen debunked in straight news reporting.
The articles quoted activists or advocacy reports that other reporters had picked apart months earlier. I wanted to know: how often does this happen, and does it happen equally across the political spectrum?
Searching for keywords doesn’t answer that. Half the articles mentioning a claim are debunking it, not spreading it. What matters is stance – does the article treat the claim as true, or not?
How the pipeline works
The tool runs in five stages. Here’s the short version:
- Collect – Pull news articles from MediaCloud on women’s health topics.
- Sort – Label each article as a fact-check, original reporting, or other.
- Extract – Pull the debunked claims out of the fact-check articles.
- Match – Find original articles that may be repeating those same claims.
- Verify – Have an LLM decide whether each matched article is carrying the claim as fact.
The verifier labels each match as one of four things: carrying (states the claim as fact), debunking (refutes it), neutral reporting (mentions it without endorsing it), or irrelevant.
Every flagged article comes back with a quoted passage from the article as evidence. After the verdict, the tool checks that the quoted passage appears word-for-word in the article. Anything paraphrased gets thrown out. This prevents the AI from making up evidence.
The diagram
MediaCloud --> scrape --> topic gate
|
v
Stage 1: classify [qwen3:14b]
FACT_CHECK / ORIGINAL / OTHER
|
+--------+---------+
| |
v v
Stage 2: extract Stage 4a: embed
claims from ORIGINAL chunks
FACT_CHECK [nomic-embed-text]
[qwen3:14b]
| |
v |
Stage 3: ideology |
cross-ref filter |
(>=2 buckets or |
authoritative-solo) |
| |
v |
Stage 3.5: normalize |
claim families |
| |
+---------+--------+
|
v
Stage 4a: retrieve top-K
candidate pairs
cosine similarity >= 0.65
|
v
Stage 4b: LLM verify
[gpt-oss-safeguard, temp=0]
carrying / debunking /
neutral / irrelevant
|
v
Stage 5: provenance bundle
FINDINGS.md
carriers_by_article.csv
misinfo_carriers.csvThe tool runs on two machines. A cheap Linux box does the scraping around the clock. A separate GPU machine runs the AI models and only turns on when needed.
Why I swapped out the AI model mid-project
The first version used qwen3:14b for everything. It was fine. But I wanted to know if a different model would be more accurate, so I tested five of them head-to-head.
I created a test set of 100 articles where I already knew the right answer. I had Claude Opus 4.7 score each one, then compared all five models against those scores:
| Model | Accuracy | Carrier precision | Carrier recall | F1 |
|---|---|---|---|---|
| gpt-oss-safeguard:latest | 0.83 | 1.000 | 0.542 | 0.703 |
| phi4:14b | 0.71 | 0.654 | 0.625 | 0.640 |
| qwen3:14b (incumbent) | 0.64 | 0.680 | 0.625 | 0.652 |
| phi4-reasoning | 0.58 | 0.560 | 0.380 | 0.450 |
| gemma3:12b | 0.40 | 0.580 | 0.625 | 0.600 |
gpt-oss-safeguard was built specifically for safety and judgment tasks. It flagged fewer carriers than qwen3 (90 vs. 198), but it was nearly perfect when it did flag something.
For a public list of named outlets, fewer false positives matters more than catching everything. A wrong accusation is harder to walk back than a missed flag.
Final accuracy numbers
After switching models, I ran a larger test on 641 articles. Claude Opus 4.7 judged all of them. Results:
- Carrier precision: 0.973 – of every article the tool flagged, 97.3% were real carriers
- Carrier recall: 0.692 – the tool caught about 69% of the real carriers in the test set
- Overall accuracy: 0.778
That means the 187-flag list has roughly 182 real carriers and about 5 false positives.
Why a human still has to check every flag
97.3% sounds like you could publish straight from the spreadsheet. You can’t.
The ~5 false positives aren’t spread randomly. They almost always come from the same situation: an outlet that debunks a claim by quoting it first. The tool sees the quoted claim and flags the article as a carrier. The article is doing the opposite of carrying the claim – but the AI gets confused.
For example: CBS News published an article titled “Kennedy says FDA is reviewing safety of abortion pill mifepristone.” The article quotes RFK Jr. and Dr. Marty Makary citing an Ethics and Public Policy Center report saying mifepristone causes serious complications and needs stricter oversight. Later in the articile contributor Dr. Celine Gounder is quoted saying: “Other data sources show the rate of serious complications to be much lower, at less than 1 in 200.” qwen3 weighted the Kennedy and Makary quotes and classified the article as supporting misinformation.
This is the worst possible error pattern. The outlets most likely to get wrongly flagged are the ones doing careful debunking work. Publishing a wrong flag there causes real damage.
The fix is manual but fast. Open the misinfo_carriers_by_article.csv file that the tool created, click each URL, and read the article. Check that the quoted evidence matches what the tool said, and that the article isn’t refuting the claim. Most rows take 30 seconds.
The published list in docs/FINDINGS.md (linked below) is the post-review version. The raw CSV is not ready to publish. This review step is part of the process, not optional cleanup.
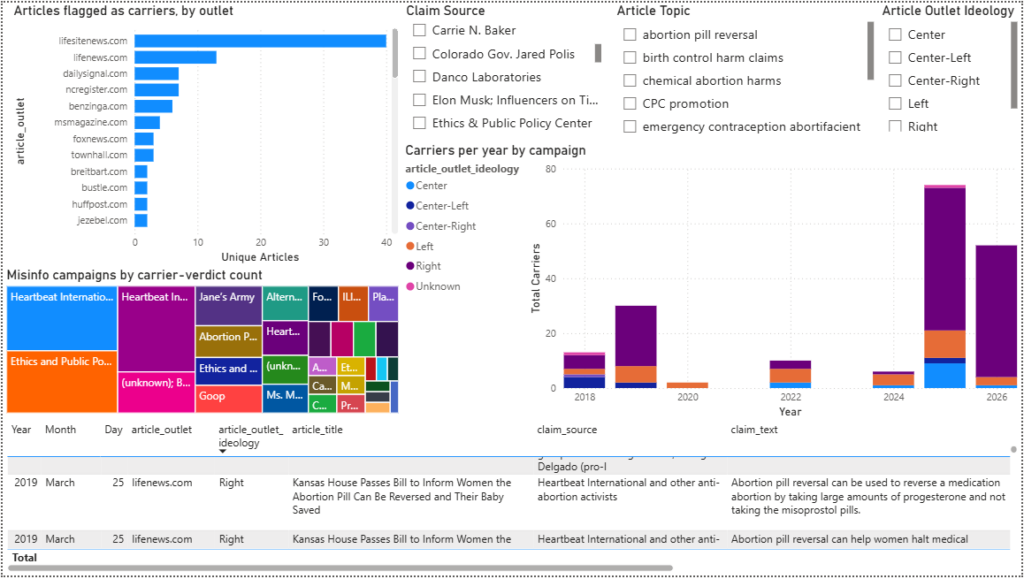
What it found
Campaign 1: Abortion pill reversal
Heartbeat International and allied outlets account for about 70 of the 187 carrier verdicts. The claim takes several forms: the reversal procedure exists, it’s safe, it can stop a medical abortion, and progesterone is the treatment.
ACOG has called the protocol “not based on science.” Multiple fact-checks in the corpus agree. The carrier articles present it as proven – usually through personal stories like “She reversed the abortion pill and saved her baby’s life.”
The claim shows up on lifesitenews, lifenews, foxnews, dailysignal, ncregister, and smaller outlets.
Campaign 2: The EPPC mifepristone report
A 2025 Ethics and Public Policy Center report claimed 1 in 10 women experience “serious adverse events” from mifepristone. CBS, the AP, and others took it apart. The report mixed ER visits with serious complications, included pre-existing conditions, and used a non-representative database.
Twenty-six carrier verdicts cite the report’s numbers without mentioning any of that. These articles don’t use personal stories – they just cite the report as authoritative.
It goes both ways
This is the finding most people won’t expect: a Planned Parenthood comparison (“mifepristone is safer than Tylenol or Viagra”) was repeated without caveats in CNN, NewStatesman, Vox, Slate, Bustle, Jezebel, MS Magazine, and others.
Several fact-checks in the corpus called that comparison misleading. It compares death rates across drugs with different doses, user groups, and risk profiles. That context was missing from the left-leaning outlets that repeated it.
And then there’s Goop
Goop’s “botanicals support hormonal balance” framing for menopause turned up across press-release outlets. benzinga.com alone produced 6 carrier verdicts on this one claim, despite a Business Insider debunking in the corpus.
This is the most boring kind of misinformation: advertorials published as if they were reporting.
Carrier totals by outlet
| Outlet | Carriers | Articles |
|---|---|---|
| lifesitenews.com | 65 | 40 |
| lifenews.com | 23 | 13 |
| dailysignal.com | 12 | 7 |
| ncregister.com | 9 | 7 |
| benzinga.com | 6 | 6 |
| foxnews.com | 6 | 3 |
| msmagazine.com | 4 | 4 |
| (49 more outlets) | 1-3 each | 1-3 each |
Full table: docs/FINDINGS.md.
Three things that surprised me
1. The tool can only find what’s already been debunked
The tool works by matching articles against a library of debunked claims. If a claim has never been fact-checked – or that fact-check isn’t in this corpus – the tool will never flag it.
An outlet with zero flags isn’t necessarily clean. It might just be spreading claims nobody in this corpus has debunked yet.
2. Fixing the false-positive problem is harder than it looks
Every time I tried to adjust the AI prompt to fix the debunking-article false positives, it started missing real carriers instead. The two problems are structurally linked.
The real fix is a second classifier that runs first and asks: “is this article about misinformation?” before the main verifier ever sees it. I haven’t built it yet.
3. The AI was making up its own evidence
In early runs, the AI would flag an article and provide a quote from it as evidence. But 29% of those quotes didn’t appear word-for-word in the article. The AI was paraphrasing or hallucinating text and presenting it as a direct quote.
Adding an automated check that verifies every quote against the actual article text dropped the error rate to 0%. The broader lesson: always verify AI citations with code and human review, not trust.
What I’d do differently
More fact-checks. This run used 91 fact-check articles and caught 300 debunked claims. That’s enough to spot concentrated campaigns but not a wide range of misinformation. The next version pulls from the Google Fact Check Tools API. The scaffolding is in pipeline/external_factchecks.py.
A wider time window. Some carrier articles cite reports from 2017-2019. The 8-year window I used was too narrow for some claim families. The expansion plan is in docs/SCOPE_EXPANSION_PLAN.md.
Technical notes for builders
This runs on consumer hardware (RTX 4080, 16 GB VRAM). The full pipeline takes a few hours end-to-end. Two settings that will trip you up:
- Keep
num_ctx=8192forqwen3:14b. Bumping to 16384 spills to CPU and runs about 6x slower. - Set
"think": falseat the top level of/api/generate, not insideoptions. If you put it in the wrong place, the model fills its output buffer with internal reasoning and returns an empty response. This took longer to debug than anything else in the project.
gpt-oss-safeguard won’t work with Ollama’s format=schema setting. Skip schema enforcement for that model and validate the output yourself afterward.
Claude Opus 4.7 was worth the cost for the gold set. Having it judge 641 articles was faster than doing it myself, and the cases where it disagreed with local models were exactly the ones I needed to look at.
What’s available to use
- Repo: github.com/rickramos1/ai-media-analysis-tool – all pipeline scripts, a gotcha catalog, design notes, and the full carrier table.
- Carrier dataset: every flagged article with the originating claim, debunking outlet, quoted evidence, and AI reasoning. File:
data/misinfo_carriers_by_article.csv. - Test set and bake-off tools: the 641-row labeled set and the model comparison scripts are in the repo. Prompts are in the scripts.
If you’re researching women’s health media coverage, the carrier dataset is yours. Every row has a full source trail. If you’re building a similar tool for a different topic, pipeline/gold_set_bakeoff.py will likely save you a week.
Open question: Has anyone solved the debunking-article false-positive problem cleanly without adding a second classifier? Every prompt fix I tried hurt recall somewhere else. I’d genuinely like to hear how others have handled it.
Leave a Reply